Building Deep Research Agent for Job Title Personalization

One Friday evening, my CEO tossed me what sounded like a quick task: “Get every customer’s job title so Odin can give our customers personalized insights based on title” I pictured a five-minute call to some third-party services API. Instead, I ended up staring at half-baked results, wondering how we had spent money on garbage data. That moment—frustration, disbelief, and the realization that our insights were only as good as the profiles behind it—ignited a mission: make our own deep research engine powerful enough to get a job done with over 90% accuracy.
The Limits of External Enrichment
Main reason why third-party enrichment services did not work for us:
- Low Coverage: The vendor could only provide titles for about 40% of our users. The majority came back empty.
- Questionable Accuracy: Even among those 40%, we spotted errors – old titles, generic placeholders, or mismatched people. Relying on this data risked misleading Odin’s insights.
- High Cost: Each lookup carried a fee. At our scale, it added up fast. Paying for incomplete data (and manually fixing mistakes) wasn’t cost-effective.
In Odin’s case, missing or incorrect job titles meant missed personalization opportunities – e.g. failing to recognize a VP of Marketing vs. a Sales Rep, which should change the tone and content of AI-generated analysis. Rather than accept the patchy results or drain our budget on more API calls, we decided to build our own “deep research” system to find job titles autonomously.
Crafting a Deep Research Stack In-House
Instead of outsourcing, we engineered a custom deep research agent stack to automatically search for and extract user job titles. This wasn’t a simple script or single prompt – it was a full pipeline of AI reasoning, web search, crawling, and validation. We treated the problem like an open-ended research question: “What is Jane Doe’s current job title?” and built an AI agent to find the answer with high confidence.
Our solution centers on an OpenAI function-calling agent augmented with tools. Here’s how we designed the stack:
- LLM Orchestrator (Brain): We use an OpenAI GPT model (via function calling) as the agent’s brain. It reads a user’s name (and any known context like company or location) and decides how to find their job title. The LLM can call various tools we defined – like web search and web scraping functions – in a structured way. This agent handles the reasoning: which sites to query, how to interpret results, and when it has enough evidence to answer.
- Web Search Tool (Eyes): The first tool is a search function that queries the web for the user’s name alongside keywords like “profile” or “job title”. The agent uses this to get a list of candidate pages (e.g. professional social profiles, company team pages, press releases) likely to mention the person’s role. We tuned the search queries to increase precision – for example, including the person’s company or email domain if we knew it, to narrow results.
- Web Crawl & Scrape Tool (Hands): Finding a likely page is step one; next the agent needs to extract the title from it. We built a crawler function that takes a URL from search results and returns parsed text (or relevant snippets) to the LLM. The agent then scans the text for a job title string (like “Jane Doe – VP of Marketing at Acme Corp”). We had to be careful with this step: the agent uses its reasoning to skip unrelated content and pinpoint the exact title.
- Answer Formatting Function: Once the agent thinks it found a title, it calls a formatting function to standardize the output (e.g. ensure it returns “VP of Marketing at Acme Corp” and nothing extra). This function helps maintain consistency in how Odin stores and uses the title. It’s essentially a final cleanup step.
- Iterative Reasoning Loop: If the first search result is inconclusive or the page text is ambiguous, the agent can loop: refining the search query, trying another result, or using alternate strategies (for example, searching on a different domain). We allowed the LLM agent to make multiple tool calls in a chain – a controlled depth of reasoning – until it’s confident in an answer or determines that the title is not found. Designing the right function call depth was important: too shallow and we’d miss answers, too deep and we risked long runtimes or getting stuck. Through automated evals, we found a sweet spot (usually 1-3 search+crawl iterations) that solved most cases without excessive cost or latency.
Throughout this process, the LLM agent is the orchestrator – it decides which tool to use when, and how to interpret the information retrieved. We defined clear tool schemas for inputs/outputs (e.g. the search function returns a JSON of top results with titles and URLs, the crawl function returns page text) so the LLM could reliably parse and act on them. Crafting these schemas and prompts was an exercise in prompt engineering and software design: the agent’s “API” had to be intuitive for the LLM to use correctly.
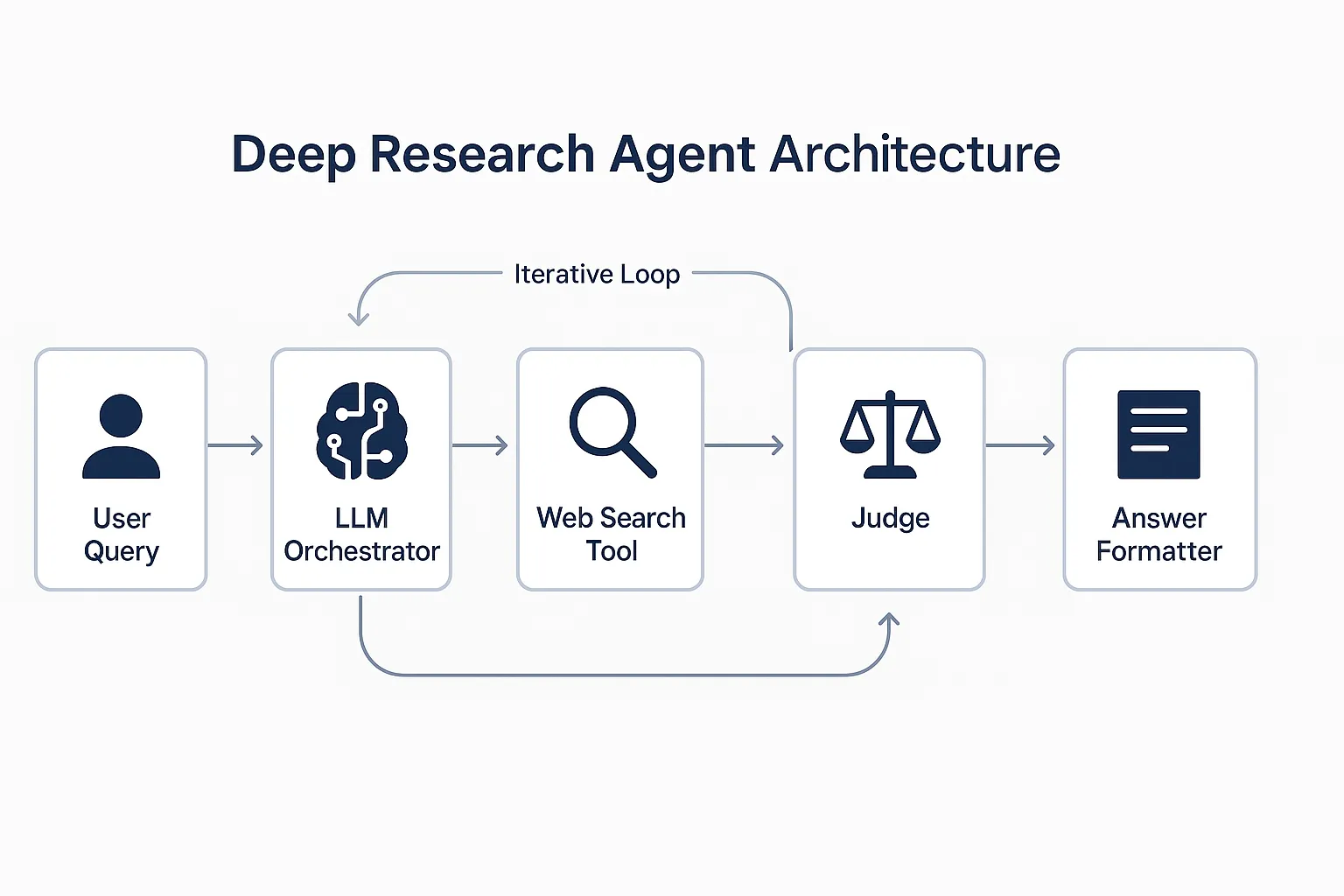
Confidence Checks with a “Judge-Answer” Circuit
One of the most impactful design choices was adding the “Judge” model to validate answers. This idea was inspired by our experience with multi-step LLM pipelines, where having the model critique its own output significantly boosts accuracy. In our job title agent, the judge is essentially a final auditor:
- The judge is an LLM (we use a larger model for this step) that takes the candidate job title along with context (like the snippet of page it came from or the search results) and answers questions like: “Is this title likely correct and current for the given user? How confident are we?”
- If confidence is high (we set a threshold that roughly corresponds to >90% certainty), the judge approves the title. If not, it might flag issues (e.g. “This title appears to be from an old press release in 2019” or “Multiple people named John Smith found – ambiguous”).
- When the judge flags a problem, the agent doesn’t just give up. It goes back into research mode: maybe searching for a more specific query (“John Smith Acme Corp 2025”) or trying an alternate site. Only after a second attempt fails would it concede that the title can’t be found confidently. This loop ensures we maximize accuracy – the agent essentially learns from the judge’s feedback and tries to fix the answer.
By making the judge a mandatory checkpoint (not just an optional tool), we prevented the agent from prematurely returning dubious data. The agent knows it must satisfy the judge before finishing, which encourages more careful reasoning and use of evidence. This judge-agent interplay formed a reliable circuit: answer, critique, refine – resulting in far more trustworthy outputs.
Handling Missing or Ambiguous Data
Real-world data is messy. Some users simply don’t have a public professional footprint, and some have common names that yield too many hits. Our deep research agent had to smartly handle cases where the job title was missing or ambiguous:
- No Results Found: If the web search comes up empty or only irrelevant pages, the agent recognizes it early. The judge can also reinforce a “no data” scenario (e.g., “No profile found for this person”). In these cases, the agent returns a result indicating the title is unknown, rather than hallucinating one. We’d rather have Odin say “I don’t have that info” than use a wrong guess.
- Common Names Ambiguity: For users with common names, the agent leans on any extra info we have – like company, location, or even a middle initial – to refine searches. For example, searching “John Smith ABC Corp VP Sales”. If ambiguity remains (multiple John Smiths), the judge will catch the uncertainty. Our system might then output something like “Title unclear – possibly multiple people with this name” instead of risking a mis-identification.
- Outdated Information: The web is littered with old information. The agent cross-checks dates and sources when possible. If it finds a title in a 5-year-old article, it will try to confirm if that’s still current (perhaps by finding a more recent profile). We also designed prompts to prefer sources likely to be up-to-date (for instance, official profiles or recent news). The judge model was particularly good at sniffing out stale info and prompting another search.
- Partial Data: Sometimes a search might only reveal a role without the company, or vice versa. In these cases, the formatting function might merge data from multiple sources (e.g., “Software Engineer at [Unknown Company]” if the company isn’t found). However, we generally instructed the agent to only return high-confidence titles. So if part of the information was missing, often the outcome was to mark it as incomplete rather than fill with a guess.
By anticipating these scenarios, we made the agent robust. It doesn’t break or hallucinate when data is sparse; it adapts. Roughly 15% of our users fell into the “cannot find confidently” bucket after all attempts – and that’s okay. Those can be changed by users manually in our platform. The key was designing the agent to know when to stop and say “I don’t know” – an often underrated aspect of AI system accuracy.
Results: 2× Coverage and Higher Accuracy
The outcome of our custom deep research system was immediately rewarding:
- Coverage jumped to ~85%: We obtained reliable job titles for over 85% of our users. This is more than double the coverage we got from the paid enrichment (40%). Odin can now personalize answers for the vast majority of our users.
- Confidence > 90%: Thanks to the judge mechanism and careful tool usage, we estimate over 90% of the titles are correct. In testing, we spot-checked hundreds of results and found very few errors. The combination of live web data and AI reasoning outperformed the static, patchy vendor database by a wide margin.
- Cost Efficiency: Our solution runs on API calls and custom code, with negligible cost per lookup (a few fractions of a cent in compute). In contrast, the enrichment provider charged a significant fee per record. By building in-house, we saved money while improving quality. The engineering effort paid for itself quickly given ongoing needs.
- Freshness and Control: The internal agent fetches real-time information. If a user changed jobs last month, the web likely reflects that, whereas third-party data might lag. We also have full control – if we need to tweak the search strategy or update the formatting, we can do it in our code, no waiting on a vendor. This agility means Odin’s personalization will only get better over time.
Perhaps the most telling result: Odin’s users (internal teams and beta customers) noticed the difference. With personalized context (“As a Sales Manager, you may focus on X metric…”), the AI’s responses felt more relevant. And we achieved this without any additional input from users – the intelligence was gathered automatically behind the scenes.
Closing Thoughts
Building Odin’s job title research agent taught us several valuable lessons about applied AI engineering:
- Specialized Agents > Off-the-Shelf Data: By tailoring an AI agent to our specific task, we beat a generic data provider. This reinforced our belief that small, purpose-built LLM agents can outperform one-size-fits-all solutions when you have a well-defined problem. The key is understanding the problem domain (in this case, professional profiles) and giving the agent the right tools and guidance to navigate it.
- Tool Orchestration is Powerful: Allowing the LLM to use tools (search, crawl, etc.) made it far more capable than just prompting it with what we knew. It could discover new information. However, orchestrating these calls required careful design – we had to prevent infinite loops, handle errors (like a webpage not loading), and ensure the agent stayed on track. A lot of “engineering craftsmanship” went into prompt design and function interfaces to make the agent both creative and reliable.
- Always Have a Back-Stop (Judge): The judge-answer pattern proved crucial. It’s like a safety net that catches mistakes before they reach the end user. This gave us confidence to deploy the system at scale. We’ll continue to use this pattern in future AI agents where accuracy matters. One insight: the judge doesn’t even add much latency since it often runs on a smaller input (just the candidate answer and some context). It’s an easy trade-off for peace of mind.
- Handling Uncertainty: We learned to embrace the cases where the AI can’t be 100% certain. Rather than force an answer, the agent’s ability to recognize ambiguity is a strength. It keeps Odin’s output honest and trustworthy. In production, we log these uncertain cases for potential human follow-up or future improvements (they’re great for identifying gaps in our approach).
What’s next? We plan to extend this deep research approach to other profile data that can enrich Odin’s intelligence – for example, company firmographics, industry news about the user’s organization, or even personalized benchmarking data. Each of these could be a mini research problem for an AI agent to tackle. We’ll also look into a “shallow research” mode for easier questions, using lighter-weight methods when a quick database lookup might suffice, and reserving the heavy web crawling for truly unknown data (this kind of tiered approach can optimize cost and speed).
By building the job title agent, we not only solved the immediate personalization need, but we also developed a blueprint for deep research tasks within our platform. Odin is now backed by an army of specialized mini-agents – crafted with the same care as this one – to ensure our AI’s insights are as relevant, accurate, and up-to-date as possible. The experience underscored that with the right engineering, an in-house AI solution can absolutely outperform paid enrichment, delivering better results at lower cost. And perhaps most importantly, we gained a deeper understanding of our own data and users in the process – a win-win for our AI and our team’s expertise.
We’re excited to keep pushing the boundaries of what Odin’s specialized agents can do, and we’ll continue to share those learnings in our Applied AI series.