Build vs Buy: The Stack You Can't Reasonably Build

Revenue AI that actually runs in production isn't "LLM + APIs."
In one line: The choice isn't "buy a generic AI tool" or "build a chatbot." It's whether you're willing to build a unified revenue data layer, an ML system that learns from actual wins and losses, and a workflow engine that compiles to auditable, resumable runs. Or adopt a platform that already did.
The prototype takes a sprint. Connect the CRM, call the LLM, get something useful back. It works, and it feels like the hard part is done. Then you try to run it across a full book of business and it times out. Fix that and the identity resolution breaks. Fix that and a workflow fails on step 6 of 12 with no record of what ran before it. Six months in, the team is deep in data engineering and nobody's touched a prompt in weeks. That's not a detour. That's the build.
What ships in production isn't a thin wrapper around a model. It's a full stack in three layers: data foundation, intelligence layer, and execution. Each has a real build cost and specific things generic approaches can't replicate.
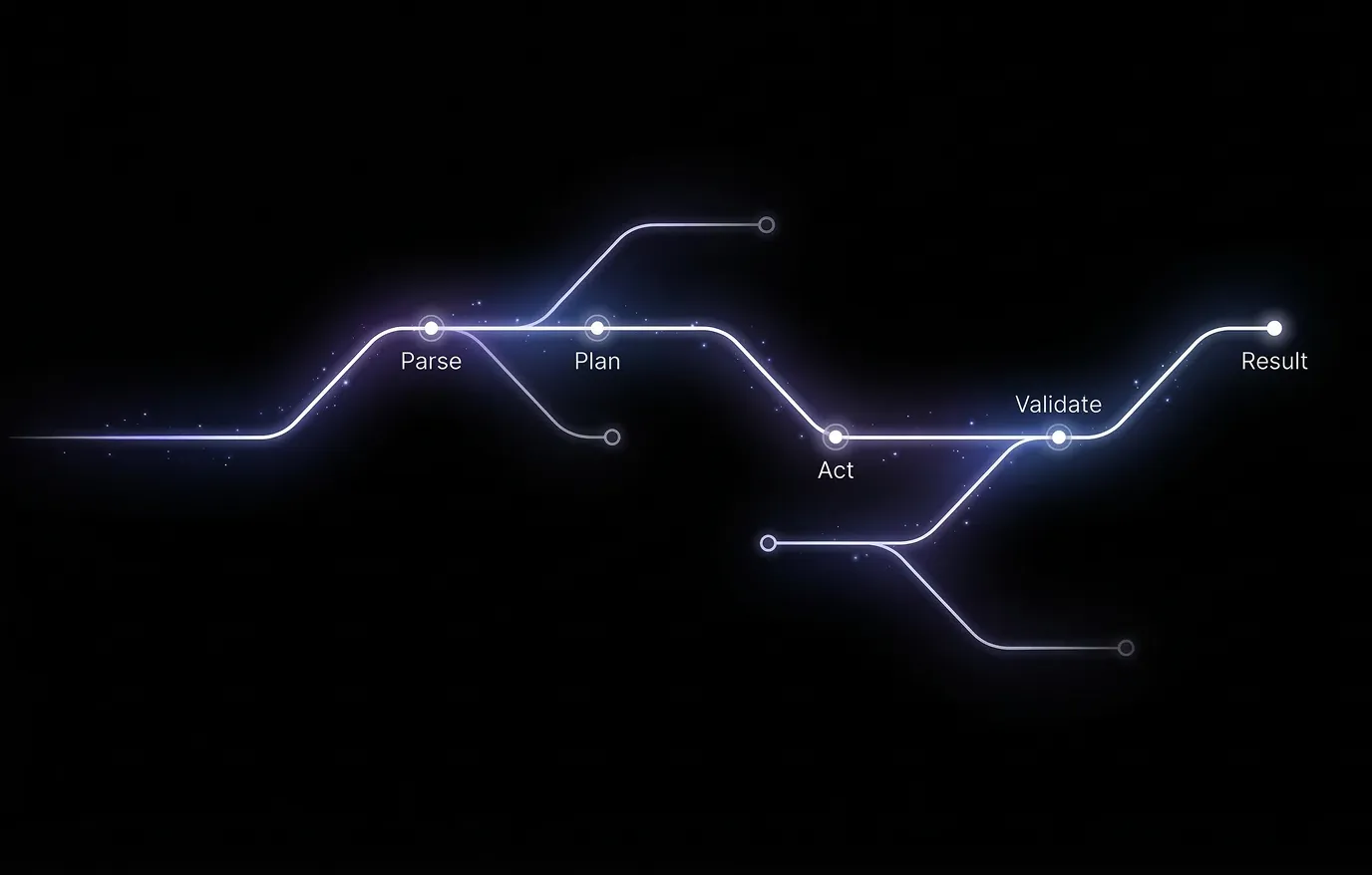
System overview: three layers
The full system flows top to bottom. Each layer feeds the next.

Data Foundation (Atlas). One unified, machine-digestible view of all GTM data. Identity resolution, event-chain processing, and business-context categorization turn raw sources into a single model the rest of the stack runs on.
Intelligence Layer (Blueprints). Discovers winning patterns from data (fit + behaviors → outcomes), produces process and execution guidance, and feeds that into the execution layer.
Execution (Agents). A contract in natural language compiles to a validated workflow; the engine runs it with GTM-native operations and guardrailed actions. Tasks and feedback close the loop back to intelligence.
What "build" is usually assumed to be
The mental model most teams start with: grab an LLM API, connect the CRM and a few other sources, write good prompts. The prototype works. What it doesn't give you is a data foundation where "deal," "contact," and "first touch vs last touch" mean something specific to the system, not something recalculated in every query. It doesn't give you a workflow that runs the same way each time because it was compiled from a contract, not re-interpreted from a prompt. And it doesn't give you any guarantees about what happens when a run fails halfway through.
LLM + APIs + prompts is not the same as building what enterprises need for revenue workflows. The gap is all three layers below.
1. Data Foundation (Atlas)
Revenue questions are temporal and relational: first touch, last touch, full story before the call, which deals haven't had a meeting in 14 days, which contacts on the deal were in the last meeting. The data layer has to make those questions native. This is Atlas: the data platform everything else is built on.
What you have to build
Unifying all GTM data. Complete capture across the GTM stack: CRM, call recording (full transcripts, not just summaries), sales engagement, data warehouses, third-party enrichment, and real-time sources. Each integration needs connectors, schema mapping, and error handling.
Resolution (the critical differentiator). Two distinct resolution processes that most in-house agent efforts skip, and then fail on. Identity resolution merges duplicate entities: a single person can appear as Contact, Lead, Campaign Member, and Event Attendee in one CRM, and the agent has to know they're the same person. Metadata resolution connects related data across platforms. It links a call recording to the CRM meeting it belongs to, so "this meeting" points to "this deal" without the agent having to infer it. These sound like implementation details. They're where agents break in production.
Then event-chain processing (temporal sequencing, recency, causal relationship tracking) and categorization (funnel stages, segments, personas) so pattern matching runs on business reality, not arbitrary CRM fields.
The core primitives aren't accounts and contacts. Timeline handles all activities in temporal order, with recency built in. Activity covers typed interactions with causal relationships native to the model. Entity handles companies and people that merge across systems, with deterministic graph traversal. The shape of these primitives is what makes downstream queries like first touch, deal story, and next best action answerable without rebuilding the logic in every workflow.
The design principle throughout: keep business context as an overlay rather than baking it into the raw data model, and optimize the format for machine consumption. Building it is a multi-year project: schema design, resolution logic, pipelines, and ongoing maintenance as sources evolve. It's also the layer that's hardest to replicate once you fall behind, because it requires not just engineering time but months of data flowing through it before the intelligence layer has anything reliable to learn from.
Differentiators
Without a GTM-native data foundation, the intelligence layer has nothing reliable to learn from and execution runs on fragmented, inconsistently ordered data. Everything downstream is only as good as this layer.
2. Intelligence Layer (Blueprints)
The data foundation tells you what happened. It doesn't tell you what to do next. That's Blueprints' job: learn from your deal history what winning looks like, and turn that into process guidance specific enough for Agents to act on.
What you have to build
Pattern identification. The ML model pulls from both structured and unstructured sources. Unstructured means call recordings: classifying calls, extracting whether discovery questions were asked, whether next steps were established, which objections came up and how they were handled. Structured means CRM fields, engagement metrics, firmographic data. Getting the unstructured extraction accurate enough to train on requires domain expertise and a self-correcting loop.
Machine learning. The model takes fit features (company type, persona, deal size) alongside behavior features (what actually happened in the deal) and optimizes against closed-won. The goal is patterns granular enough that given a specific deal state, you get a specific next step. That requires ongoing validation against historical data as patterns shift.
Process output. Both high-level process (stage transitions, stakeholder involvement, timing guidelines) and detailed execution guidance: scoping call instructions, follow-up templates with business-case prompts, exact person and messaging. Agents run against that guidance.
Designing the feature-extraction paths, the ML layer, and backtesting is ML-ops-level work. Keeping the models accurate as deal patterns shift adds ongoing cost beyond the initial build. Many months to a year or more for a focused team.
Differentiators
Without an intelligence layer, you're running Agents against process that's guessed, not learned.
3. Execution (Agents)
Runtime isn't "invoke the workflow once." Production workflows touch real data, hit external systems, time out, and get cancelled. Agents is the execution layer, and it has four things generic approaches don't: a workflow language built for GTM objects, a compilation pipeline that validates before anything runs, a registry of named operations rather than raw API calls, and durable execution that survives failure.
What you have to build
GTM-native workflow language. Most orchestration tools give you a pipeline of generic steps, what's called a directed acyclic graph (DAG): call the LLM, call an API, branch on a condition. The steps don't know what a deal is. HockeyStack's workflow language is built around the objects revenue processes actually run on: deals, companies, contacts, events, activities. Steps are typed around those objects: iterate over a filtered record set, branch on a deal property, invoke a model, emit output. Nesting rules are enforced, so malformed workflows are rejected at build time. Data flow between steps is explicit, so there's no ambiguity about what each step has access to.
Contract-to-workflow compilation. You write the instruction in plain language. The system parses intent, validates it against the workflow language and available operations, generates a candidate workflow, corrects errors with bounded retries, and runs both a model-level and programmatic check before saving anything. Nothing executes until it passes both. After that, the same compiled workflow runs every time.

GTM-native operations. Agent steps call named operations from a GTM registry rather than raw APIs. The registry covers what a revenue workflow actually needs: fetching and filtering records, traversing associations between objects, pulling call recordings and email activity, synthesizing signals into reports, creating rep tasks with specific person, messaging, and timing, syncing to the CRM, sending messages, triggering external actions. Each operation has defined parameters, and some require iterating over records one at a time; the compiler enforces this. Fifteen-plus operations with consistent behavior across every workflow.
Durable execution. Every run executes with step-level checkpointing. If a step fails, the retry resumes from that step, not from the beginning. No redoing work, no double side effects. Run keying prevents the same logical run from executing twice. Cancellation is persisted, so cancelled runs don't come back when the orchestrator retries. Stalled runs time out. Every run is stored with a full record: what steps ran, what the output was, why it stopped. You can answer "what did this run do?" without reconstructing it from logs.
Differentiators
If you don't have a workflow language that speaks in deals and contacts, a compilation pipeline that only ships validated workflows, GTM-native operations, and durable execution, you're building a demo.
What you're really choosing
The three layers aren't parallel workstreams. Atlas has to exist before Blueprints has clean data to learn from. Blueprints has to exist before Agents knows what the workflow should actually do. The build path is sequential. You don't reach the execution layer until the first two are solid, which is what makes this a multi-year commitment rather than a sprint.
Teams that underestimate this usually end up with one piece working and the others underdeveloped. A good data pipeline with no intelligence layer means agents running on rules someone wrote in a spreadsheet. A recommendation engine with no reliable execution underneath means good suggestions that don't consistently become rep actions. The stack is only as useful as its weakest layer.
Build means taking all of that on: the sequencing, the multi-year timeline, ongoing maintenance as integrations change and deal patterns shift. It's not a decision you make once. It's a program you run continuously.
Buy means skipping the build queue. You get Atlas, Blueprints, and Agents already integrated and already running. The payoff isn't just deployment speed, though weeks instead of quarters matters. It's that you're not responsible for keeping three complex, interdependent systems in sync while also trying to run a revenue team. You define the agent, set the guardrails, and deploy. It scales the same whether you have 100 reps or 100,000.
The gap demos don't show
A working prototype and a production system are separated by these three layers. Demos look like "we called an LLM and got something useful." Production is "the same workflow runs every time, on unified data, and we can audit every run." Generic workflow tools give you pipelines and steps but not a GTM-native language. You encode deals, contacts, and events yourself in every workflow. Prompt-centric agents give flexibility but not determinism; you're hoping the model does the right thing each time.
The sophistication isn't incidental. It's the product. Atlas, Blueprints, and Agents weren't built in a sprint. They were built over years, tested against real deal data, and are running in production today. Build means starting that process from scratch, in sequence, while your quarter keeps closing. Or you skip straight to the part where it works.