The Agent Run: A Walkthrough
From contract to completed run: the mechanics that make every agent execution durable, resumable, and auditable.
In one line: You write a contract in natural language; we compile it into a workflow of revenue operators, execute the plan, with checkpoints so retries resume and cancels stick, across any trigger.
Everyone talks about the model. Almost nobody talks about the run, the thing that actually ships.
A run has three jobs: start (a click, a schedule, an API call), execute (load the workflow, run the steps, persist the result), and record what happened. Get those wrong and you get demos that time out, retries that redo everything, and no way to explain what ran on Tuesday. Get them right and your agents work with the same rigor as the rest of your revenue stack.
Contract and workflow, triggers, the orchestrator, step types, actions. Then one concrete example to see it all in motion. No code paths or function names. Just the mechanics.
Contract vs workflow: what actually runs
You don't run a prompt. You write a contract: natural language describing the goal, what data to use, what to produce. That's the source of intent. The system compiles it into a workflow: a strict, step-by-step recipe the runtime executes.
The compiler is LLM-assisted but constrained. It works within a defined spec: allowed step types, how values can reference earlier steps, what tools and actions exist. Once compiled, the validator checks that every reference resolves, the data flow is consistent, and every tool or action handle is defined. Fail validation, you get errors and can revise. Pass it, and the workflow is what gets saved. That's what runs.
Five step types. That's the whole vocabulary:
- inject — write a value into the run's context
- agent — call the LLM with tools and an optional output schema
- for_each — loop over a list
- if — branch on a condition
- output — emit the final result
Each step declares what it needs as input and where to write its result.
The agent record holds everything outside the workflow itself: display name, status (draft, live, paused), input type (none, prompt, or record), trigger configuration, and actions. Actions are how the workflow calls integrations. Each one maps a short handle to an underlying tool, with parameters pre-classified as static (you set it once: channel ID, webhook URL) or AI (the model fills it at runtime).
Contract → compiled workflow → stored. That's the build-time half. Trigger and actions define the rest.
How a run gets started: triggers
A run is one execution of that workflow. It starts when something sends a run request into the system: which customer, which workflow, trigger type (manual, test, or scheduled), and any input for this run (record IDs, a prompt).
The system creates a run record, sets it to "running," and returns a run identifier. From there, you poll a status endpoint with that identifier, watching steps complete and reading the output when it's done.
The trigger type sticks to the run the whole way through. That's what makes cancellations stick, and what prevents the same logical run from firing twice.
The orchestrator and context
When a run request comes in, the orchestrator picks it up. Its job: run the workflow all the way through and record the result.
It doesn't do it all at once. It runs one step at a time, and after each step it checkpoints: persisting the fact that the step completed before moving to the next one. If the process crashes, you know exactly where it stopped. Retry means picking up at that step. Earlier steps don't re-run. Side effects don't repeat.
The orchestrator loads the workflow and agent record (to get the actions list), then builds the initial context: a shared store every step reads from and writes to. It starts with run metadata: agent, customer, run ID, trigger type. If the run included input (record IDs, a prompt), that gets written into context first via inject steps, so later steps can reference it without re-fetching.

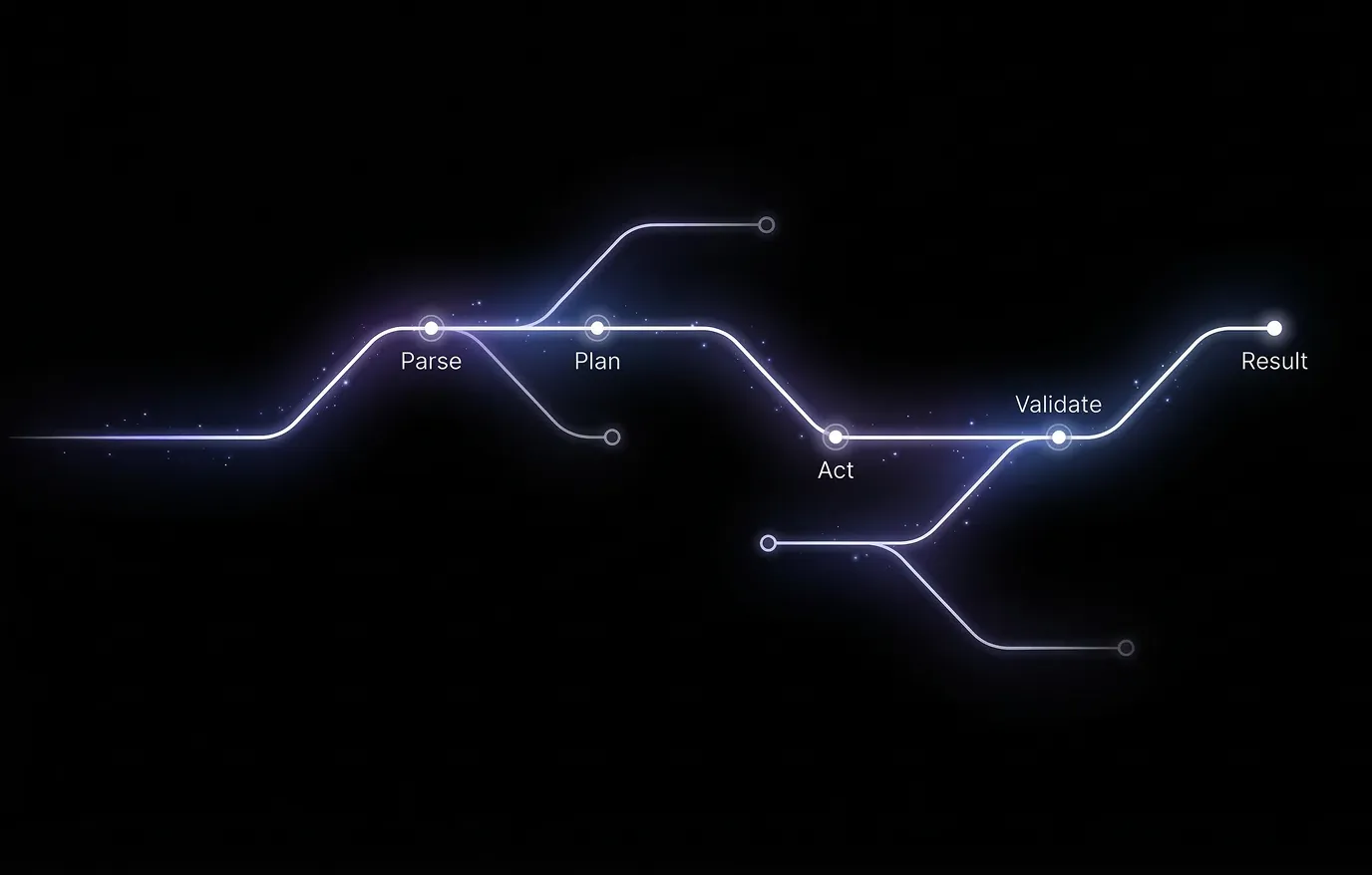
What runs in order: step types
Steps execute in the order they're defined. Each one gets a log entry, runs, and writes its result to the shared context. Then the next one runs.
Inject: Writes a value into the shared context before any model runs. Record IDs, a prompt, a config value. It's there when later steps need it.
Agent: Runs the LLM with a prompt, optional tools, and an optional output schema. Runs in a separate execution context from the orchestrator so the model loop can complete without blocking everything else. The loop: call the model; if it returns tool calls, run them, append the results, call the model again; keep going until no more tool calls or you hit the iteration limit. If there's an output schema, one final call shapes and validates the result. Only the output comes back to the orchestrator, not the full conversation thread.
For_each: Takes a source array from context and a list of inner steps. Runs those steps once per item, with a concurrency limit. When all iterations finish, per-item results get collected into an array in the main context. "For each deal, do this" → many small runs, one aggregated result.
If: Evaluates branches in order. First true condition wins; that branch runs and merges its result into context. Everything else is skipped.
Output: Resolves a key from context, validates against a schema if there is one, and marks it as the final result. Nothing runs after this.
Agent steps in detail: tools and actions
When an agent step runs, the execution context turns its config into a conversation and tool set.
Inputs: The step declares what it needs from shared context. Large values get passed by reference so the prompt stays small. The runtime resolves the actual data when the model or a tool needs it, so the model can work with it without the prompt getting bloated.
Tools and actions: Some tools are built-in (list records, get associations). Others are action handles that map to specific integrations you've configured. When the model calls a handle, the runtime resolves it to the underlying tool and merges in the static parameters, so the model only sees what it's supposed to fill, like the message body, not the channel ID. The workflow says what to call. The action config says where and how. The model fills the rest.
Model loop: Builds a system prompt (tools, global instructions) and a user prompt (step text, inputs, optional summary of what ran earlier). Then it loops: call the model; if tool calls come back, run them, append results, call again. Repeat until no more tool calls or you hit the iteration limit. If there's an output schema, one more call shapes the result. That result goes back to the orchestrator and lands in shared context. Every step after this can see it.
Finishing the run: durability and observability
When the last step completes, the orchestrator writes the final status (completed or failed), the output, and the step summary to persistent storage. The run record updates. You read the result.
Durability: Every step is checkpointed before the next one starts. A crash mid-run means a retry picks up from the last completed step: no re-work, no duplicate side effects. A cancelled run stays cancelled; the system records that explicitly and won't retry it. Every run ends in storage with its status, steps, and outcome regardless of how it finished. No digging through logs to figure out what happened.
Observability: While running, the system writes step logs (which step, inputs, timing) and tool logs (each tool call and its result), all keyed to the run identifier. The status endpoint combines all of it: run status, step list, live tool and thought logs. You see the run moving step by step. Expand any agent step and you can see exactly what the model called and what came back.
Actions: workflow vs config
Actions are how the generic workflow connects to real integrations: Slack, webhooks, CRM writes.
When you set one up, you pick an underlying tool and give it a handle. For each parameter you decide: static (set it at config time: channel, endpoint, API key) or AI (model fills it at runtime: message text, summary, subject line). At runtime, the system resolves the handle and pre-fills the static params. The model handles the rest.
"What to call" is in the workflow. "Where and how" is in the config. Swap the action config and you've got the same agent running in a different environment: different team, different channel, different destination, without touching the workflow.
Example: one run of the Closed Lost Deal Resurrector
Here's how it plays out on a real agent, the Closed Lost Deal Resurrector. Find closed-lost deals from the past 90–180 days, check for resurrection signals (website visits, email engagement, new contacts, company news), score them, create re-engagement tasks for the original deal owner, and Slack the team on high-potential ones.
Contract → workflow: Compiler produces: an agent step that pulls the deal list; a for_each over that list (per deal: fetch signals, research, score); a filtering step above the score threshold; an agent step that creates tasks and fires the Slack action; an output step. Scheduled weekly. Slack action has channel and webhook static; message body is AI.
Trigger: Schedule supervisor finds it due Monday at 6am, updates the next run time, sends the run request.
Orchestrator and steps: Context gets seeded with run metadata (no user input on a scheduled run). Steps in order: (1) Agent fetches the deal list, writes it to context. (2) For_each iterates: per deal, inner agents fetch signals and score, results aggregated. (3) Filtering step cuts to deals above threshold. (4) Agent creates tasks and sends Slack (channel/webhook from action config, body from model). (5) Output emits the result. Checkpoint after every step.
Result: Re-engagement tasks in the queue, Slack messages in the right channel. Scheduled run means nobody polled for it, but the outcome is in run history all the same. Same flow as a manual run; you'd just be polling by identifier instead.
Bottom line
You write a contract. We compile it into a workflow and validate it. Something kicks off a run: a click, a schedule, a direct API call. The orchestrator loads the workflow and actions, seeds context, and runs each step in order, checkpointing after each one. Retries resume. Cancels stick. Actions resolve at runtime. When it's done, status and output are in persistent storage.
That's the whole system. Durable, resumable, auditable. The Resurrector is just one agent running the same flow.