The Next Rung: The Case for Harness Engineering

Memory is the through-line: from absent, to curated, to first-class.
In one line: Prompt engineering optimizes the next message; context engineering optimizes what gets into the window; harness engineering builds the runtime where memory is first-class and process-shaped.
Prompt engineering: the unit of work is this request. You optimize wording, few-shot examples, format. The model has no durable state; every turn is a blank slate. Memory is absent. Powerful for one-off tasks; a ceiling for anything that needs continuity.
Context engineering: the unit of work is what the model sees. Not just the user's message: instructions, retrieved docs, conversation history, tool definitions. Memory shows up as content: what we store, how we retrieve or compress it, what gets a slot in the window. The bottleneck shifts from "how do I phrase this?" to "what do I put in the window?" Often you still rebuild or retrieve context per call.
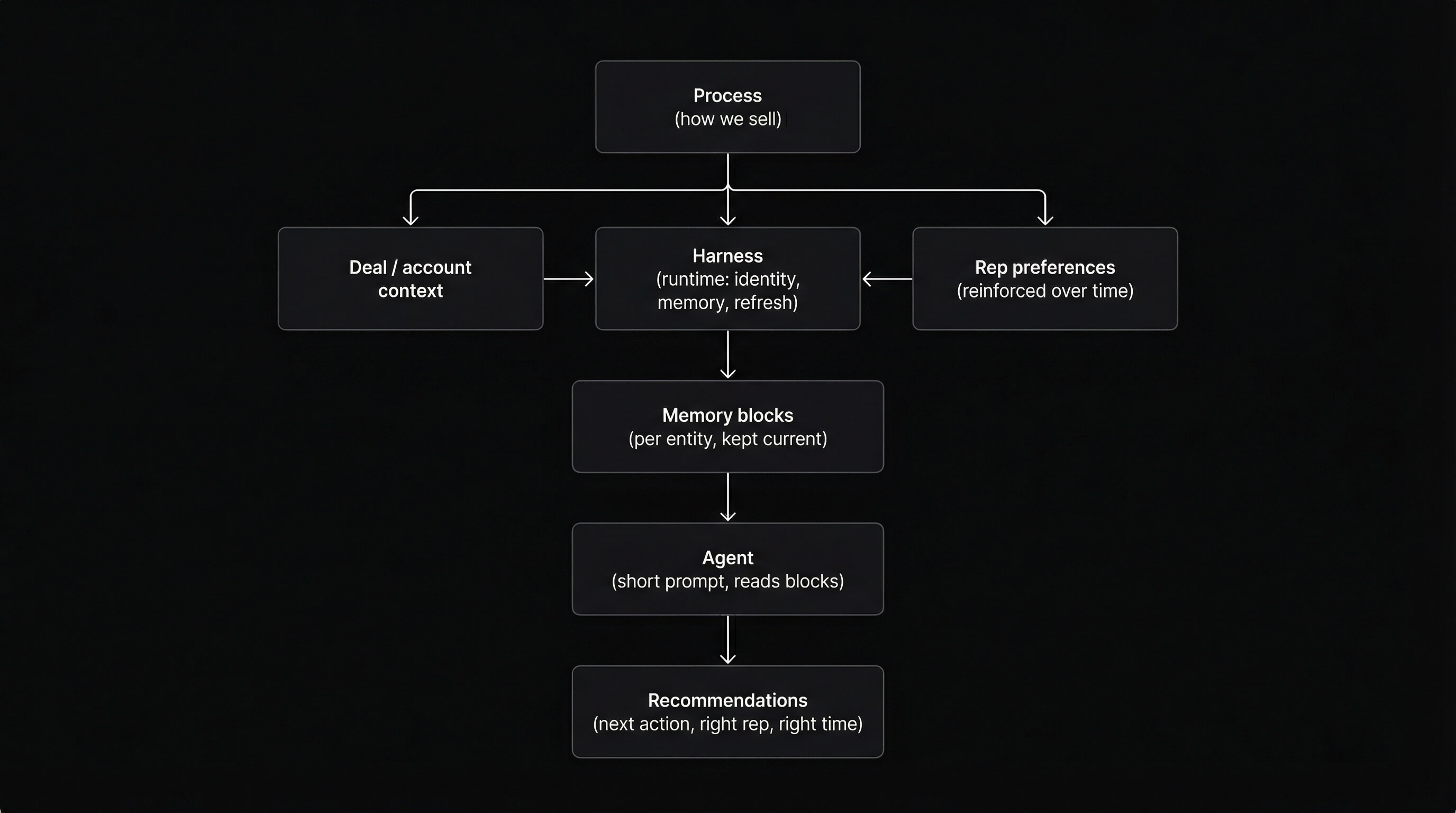
Harness engineering: the unit of work is the runtime. The harness is the purpose-built layer that wraps the model: it owns the memory, governs what context the model sees and in what order, controls what tools it can call, and manages what happens before and after each inference. The gap between calling an API and running a production agent is the harness. The API is the capability; the harness is what makes it useful for a specific process. Memory here is first-class: it gets its own schema (which blocks exist, how often they refresh, what happens when the entity changes). Because the harness is built for a specific process, memory gets domain-shaped. Not generic "user memory." Memory designed around the process the harness serves.
Memory as the through-line (and why it matters for GTM)
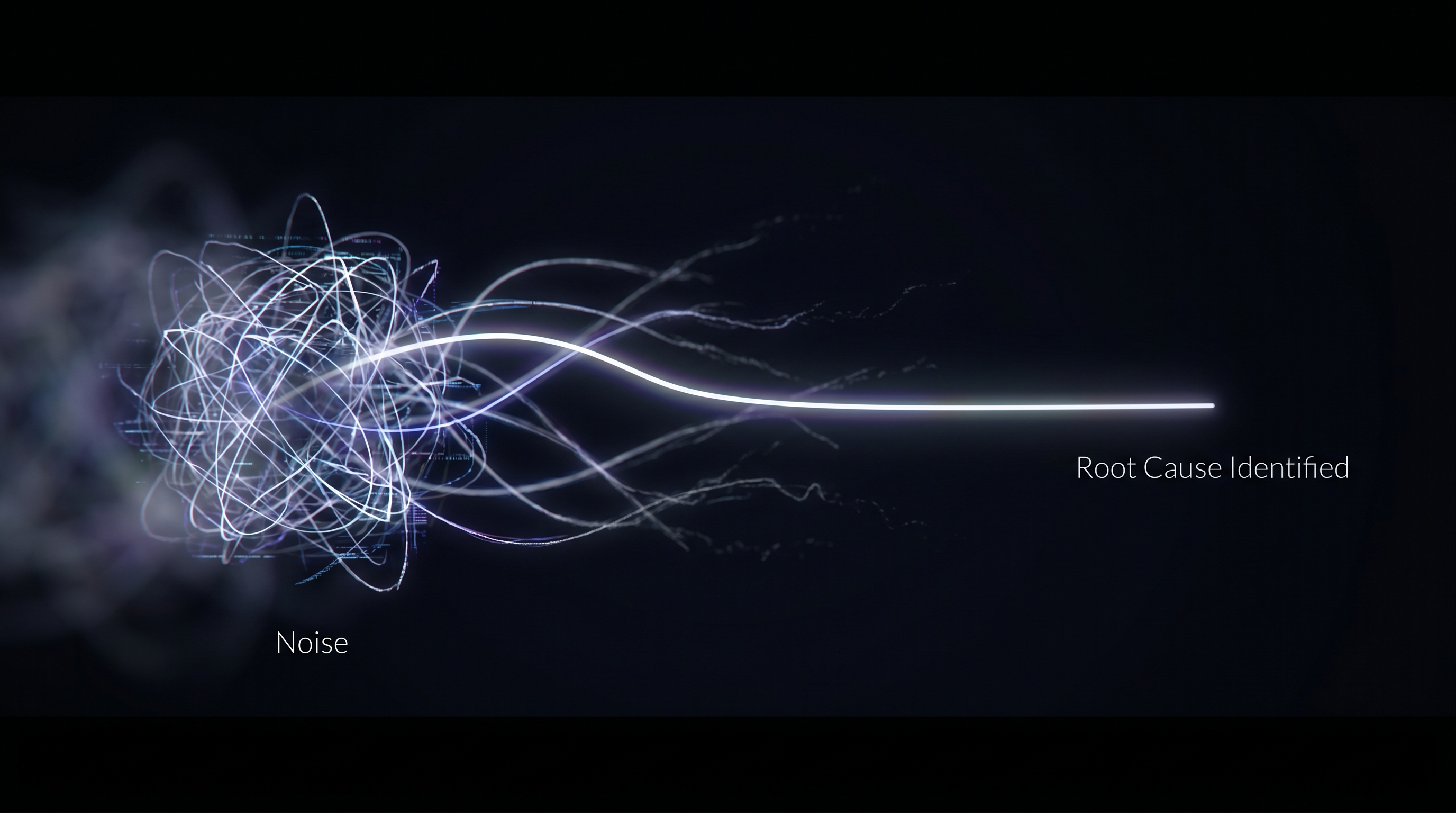
Across each rung, the real shift is how memory captures and carries forward the environment. Prompt: effectively no persistent memory. Context: memory as injected snapshots. Harness: memory as the persistent structure, retaining what survives across interactions, updating selectively, and combining with prompts and conversation. The progression is from no memory, to curated context, to memory that preserves what persists and prunes what doesn’t.
For GTM, that's decisive. Revenue happens across many touches (calls, emails, meetings, tasks) and over long cycles. If the system doesn't remember what was said, what was committed, and what the rep and the account care about, every recommendation is a guess. Memory is what gives the agent continuity: the same deal or account, the same rep, the same process, with context that compounds instead of resetting. Without it, you have a smart one-off. With it you have a system that gets better the more it's used and recommends the right next action because it remembers the last one. So when we say the bottleneck shifts from "better prompts" to "better memory inside a harness built for the process," we mean that for GTM the harness and its memory model are the product. Memory isn't a feature you add; it's the through-line that makes the process work.
The harness is not the API
There's a useful distinction between capability and harness. The API is the raw surface. The harness is the expert system around it (instructions, context, memory, workflow) that lets an agent get the most value from that capability. For GTM, your systems of record are the surface; the harness is what knows which deals and accounts matter, what's been said and done, and what the next best action is. That knowledge lives in memory that the harness owns and refreshes. You can't replicate it by turning on "memory" in a generic chatbot; you need a harness built for the process.
Process as the atomic unit
Bret Taylor (Sierra CEO and OpenAI board chair) argues that the atomic unit of productivity in AI is a process, not a person. Companies ship their org charts. They're not set up to absorb AI by department. But if you narrow to a process (onboard this supplier, resolve this support case, advance this deal), you can build a harness and memory model for that process. The more you narrow the domain, the more you can fully automate it.
In GTM, that's the same idea: the atomic unit is the sales process: the blueprint, not the rep. The harness encodes the process; the rep runs it. You're not optimizing people; you're optimizing the process they run.
So the harness and its memory should be process-shaped. For GTM, that means the harness encodes how the process works, holds what's true for each deal and each account, and reinforces how the rep likes to work over time. Entity-scoped agents, memory that matches the process, pipelines that keep it current. The schema of memory (what gets a block, what gets refreshed when) is the design of the process. Get it right and you have something you can't replicate without building it.
Most GTM teams trying to implement AI hit the same wall: they're layering agents onto systems that weren't built to have memory. Conversations reset. The agent knows nothing about what happened on last week's call, what was committed in the last email, or how this rep likes to close. Recommendations come out generic because the system has no continuity: no deal context, no account history, no rep signal. The problem isn't the model. It's that there's no harness. That's what we set out to build.
What we built
Think about the best rep you've ever worked with. They knew their deals cold. Every call, every email, every stakeholder, every commitment made three weeks ago. They ran the process and still found the plays nobody scripted: the right exec intro, the event that made sense, the relationship that needed a nudge before it went quiet. Now give that rep one deal and nothing else. That's the agent. That's the bar we set.
We didn't set out to "add memory." We set out to build a harness for the GTM process: entity-scoped agents that recommend the right next action for the right rep at the right time. The harness combines process (how we sell), deal and account context (what's true for this entity), and rep preferences that get reinforced as the system is used. Memory is the spine: each entity has a persistent agent with structured blocks we refresh when new data lands; when we ask for recommendations, the prompt is short and the heavy lift is the blocks we've been keeping current. The value is the harness and the memory model together.
Bottom line
Memory compounds. The more the harness runs, the more it knows: which signals matter for a deal, which habits stick for a rep, which patterns repeat across accounts. A team six months into this has something a team starting fresh can't close in a sprint. That's not a product advantage. It's a process advantage, and it belongs to whoever builds the harness first.