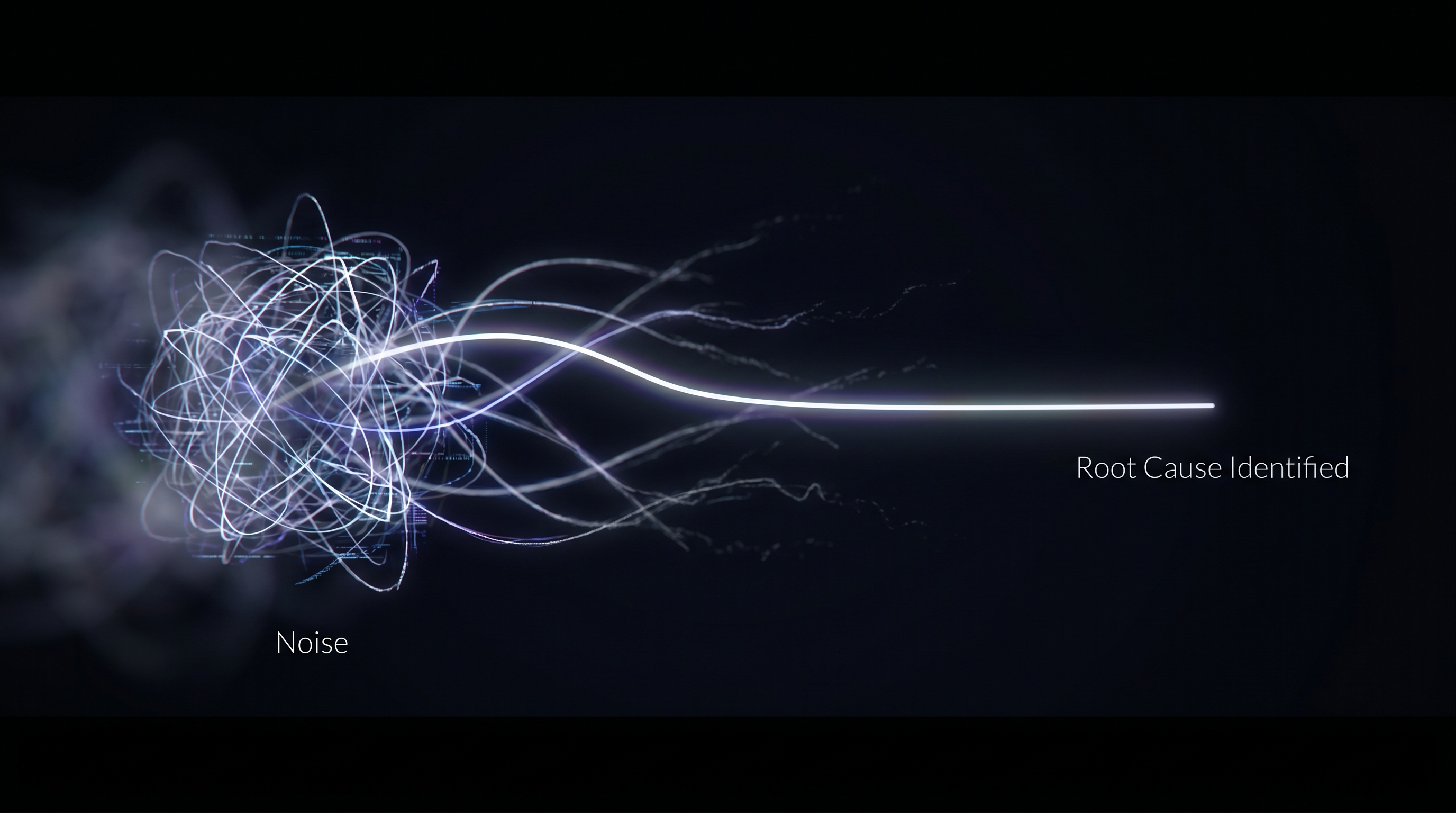
Why Enterprise AI Needs More Than Prompting
Most AI agents run on prompts. AI that drives revenue needs to run on compiled process.
In one line: Prompt-centric agents are non-deterministic by design. We compile a human-written contract (user-prompt) into a validated workflow at build time so the same input produces a consistent and reliable execution path.
The default playbook in AI right now is: write a better prompt, add more context, ship. When it works, it feels like magic. When it doesn't, you tweak the prompt and try again.
Here's what that looks like in practice. Your RevOps team builds an agent that generates next steps for every open deal overnight. Prompt-centric, it runs on Monday morning. Rep A gets "schedule a technical review." Rep B, same deal stage, same signals, gets "send a pricing proposal." Nobody can explain why. The prompt was the same. The model just went a different direction. Now multiply that across 40 deals and a VP asking why half the reps got conflicting guidance.
A lot of the industry is optimizing for prompt quality, as if the path to enterprise-grade behavior is better wording. But prompt-driven output is unpredictable in practice. Even when the model is technically capable of producing the right answer, the lack of validation, structure, and correction means you can't guarantee it will. That's fine for a summary or a draft email. It's not fine for a revenue workflow that needs to run the same way across 200 reps every morning.
The alternative isn't "no LLMs." It's about where you use them. Use the model to compile a human-written contract into a machine. Then run the machine.
The limits of prompt-centric agents
When the core loop is "send prompt, get response, maybe do something with it," the system has no build-time representation of what correct looks like. Correctness is whatever the model produced this time.
There's no schema the output must satisfy before it's accepted, no validation that the response matches your business rules, and no correction loop feeding errors back. You end up with:
Non-determinism. Same input, different output. For workflows that drive revenue or compliance, that's a non-starter.
No audit trail of intent. You can't separate "the user asked for X" from "the model interpreted it as Y." The prompt is the only spec, and it's ambiguous by nature.
Failure mode is always prompt engineering. When it breaks, the fix is "improve the prompt." That's an unbounded task, not a system with clear boundaries.
The alternative is competing on whether the system compiles human intent into something that runs the same way every time.
Reliability requires compilation, not conversation
The principle is simple. Take a contract: a structured set of instructions written in natural language that defines what the workflow should do, what inputs it needs, what steps to run, and what the output should look like. Run it through a compilation pipeline that turns it into an executable.

The pipeline uses the model where it helps, but it doesn't ship output until the result has been validated against the contract and your business rules. If validation fails, the pipeline retries or fails with clear errors so the contract can be revised.
Only when the compiled artifact passes do you run it. At runtime, the engine executes that artifact. The LLM is not deciding what to do on each request. The machine is.
You're not accepting "whatever the model returned." You're only running something that has passed explicit, machine-checkable validation. That's how you get determinism and auditability.
Build time vs. runtime
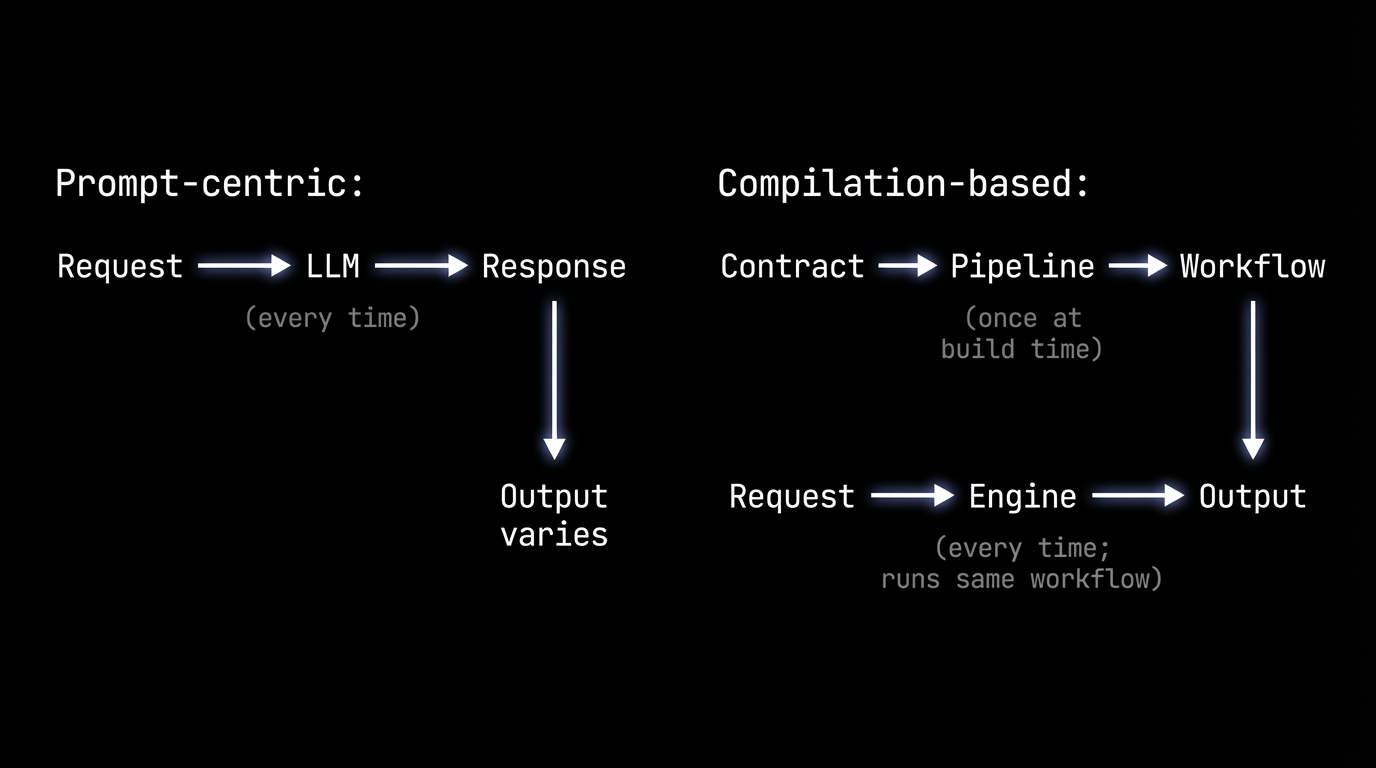
The process gets encoded into a machine at build time, validated against the contract, and executed at runtime.
What this means for enterprise AI
If your agent is "prompt in, response out," you're in the prompting game. Getting to the consistency that enterprises need for revenue workflows requires moving the uncertainty to build time and running a known machine at runtime.
This is how HockeyStack Agents work. You write a contract defining what the agent should do. The system compiles it into a validated workflow. At runtime, the engine executes that workflow, not the model. A contract goes in, a validated workflow comes out, and runtime just executes. The result is a compiled process you can audit, version, and run the same way every time.