Related Isn’t Enough: Why Revenue AI Needs a Timeline, Not a Graph


Related Isn’t Enough: Why Revenue AI Needs a Timeline, Not a Graph

Event-Based Timeline vs. Context Graphs and why it decides what your workflows can do.
In one line: Other tools treat your data as a web of connections. We treat it as a story, with a beginning, middle, and outcome, so you can act on it.
What happened with this deal? What's the full story before my call? How do I hit my number by quarter end? The answer depends on something most people never see: how your data is fed to AI. Get that wrong, and agents can hallucinate a sequence or miss why a deal actually stalled. Get it right, and you get attribution, close plans, and next-best actions that match reality.
Why Retrieval Matters for Revenue AI
To answer "What's the story with Acme?" or "Which deals should I close first?", the AI needs your data in the conversation. This is called retrieval.
RAG (Retrieval Augmented Generation) is the standard pattern: find the relevant pieces of your data, feed them to the model as context, then let it answer or act.
What matters for revenue is that retrieval doesn't happen once, it happens every step of an agentic workflow. Agentic systems run multi-step workflows: the agent gets a goal ("Build my close plan"), uses tools (get my open deals, get touchpoints for these deals, get last touch date), and decides the next step from what it found. Every tool call that touches your data is retrieval. Wrong or unordered context at any step, and the workflow can break or the model can invent the wrong sequence.

How that "related" data is stored and returned, as a set of connected things or as a time-ordered stream, is what makes or breaks those steps.
The Fork in the Road
Most systems that do retrieval over revenue data use a context graph: they store "things" (deals, touchpoints, activities) and "connections" between them. When you ask for touchpoints for a deal, they answer what is related to this deal? and return a set of items. The catch is that ordering is an afterthought: the storage model is "things and connections," not "what happened when." So every workflow step that needs first touch, last touch, or sequence has to request a sort, rely on consistent timestamps everywhere, and reapply that logic across agents, reports, and APIs. That compounding complexity is where things break down: one step gets unsorted data, one API doesn't guarantee order, the agent infers sequence and gets it wrong. This doesn’t seem right.
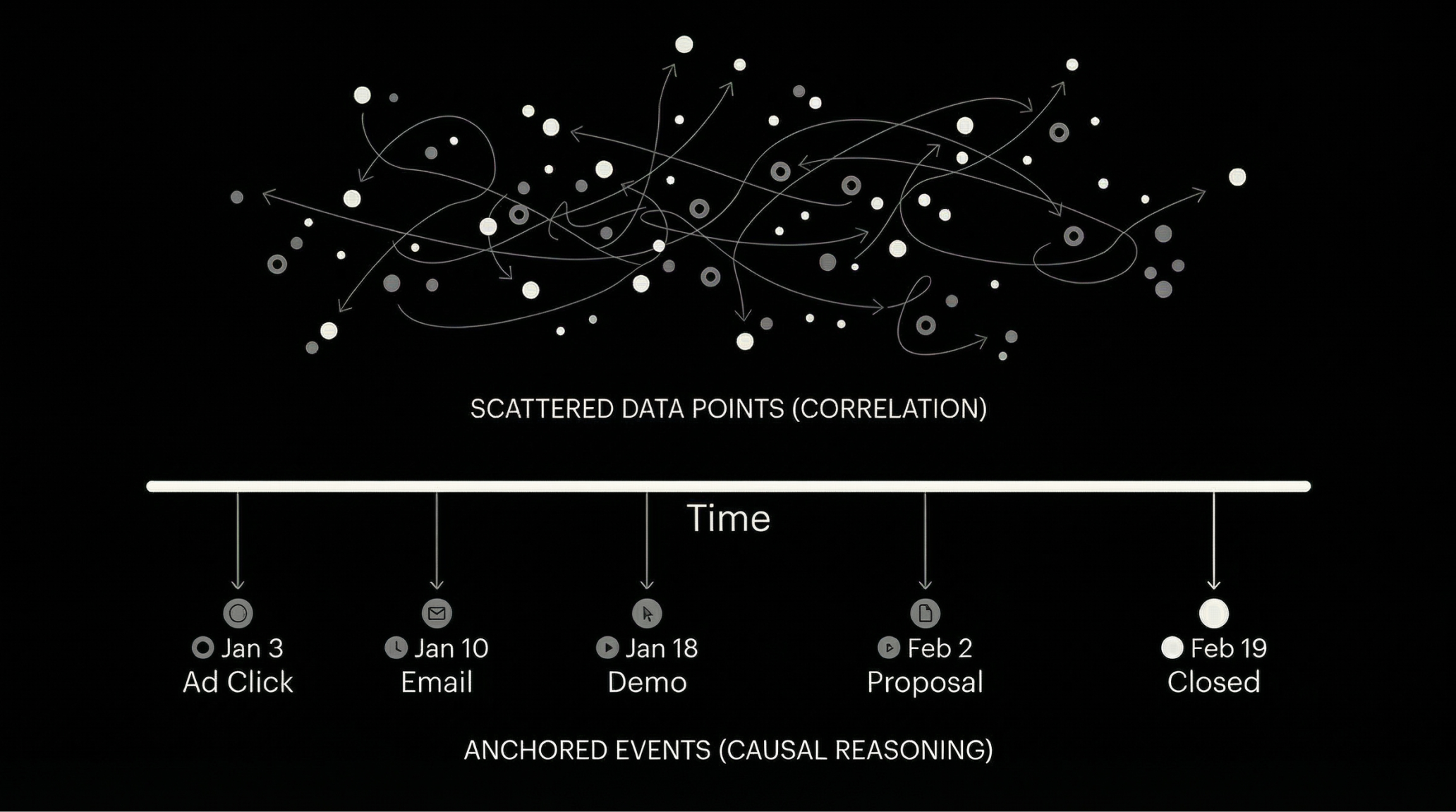
HockeyStack knows timing is everything. We store the same data as an event stream: what happened, when, for which deal. That’s the way customer journeys are built. We filter that stream and return it in time-stamped order. If order is preserved throughout, there’s no need to reconstruct timeline later, it’s already built in. First touch, last touch, and all the touchpoints in between aren't an afterthought.
Same key (your opportunity ID). Same kind of question (what touched this deal?). Different result.
What You Actually Get: Set vs. Stream
When you ask "What touched this deal? How do I replicate that pattern across other deals?":
Context graph: The system finds everything connected to that deal and hands you a set. Emails, meetings, page views, all "related." Not "ordered"—so first touch, last touch, and sequence require a sort step (and that step has to happen correctly at every layer: API, agent, report).
You get a set of related items. Order is something you add (e.g. sort by date).

Hockeystack: The system filters the event stream for that deal and hands you a timeline. Same activities—already in order. First touch is the first event. Last touch is the last. The sequence is the stream.
- Context graph:
Deal ID → find related → { A, B, C }(set; order is a follow-up step) - Hockeystack:
Deal ID → filter event stream → [ T1 → T2 → T3 → T4 ](timeline by design)
You get a stream. Order is the model.

Analogy: Context graph = a pile of sticky notes (you sort every time you need the story). Hockeystack = the same notes already in a line (the story is there).
Why This Matters
You're running a proof of concept with a mid-market account. Your champion has been pushing hard internally, but two weeks ago their VP of Engineering left the company. Since then: radio silence. Your rep asks the agent, "Why did this deal stall?"
On a graph, the system pulls 20 connected touchpoints and hands them to the model as a set. The model has to guess the order. It sees the champion's last email, the VP departure note from the HR sync, three meetings, a pricing doc view. It places the VP departure after the last meeting, because nothing in the set says otherwise. So the agent tells your rep the deal stalled on pricing and recommends sending a revised proposal. That's wrong. The real problem is that your champion lost their internal sponsor two weeks into the POC and has been flying blind since.
On a timeline, the order is already there. The VP departure lands exactly where it happened: between the second and third meeting. The agent sees the third meeting was cut short, the follow-up email went unanswered, and the pricing doc was never opened. It tells your rep: your champion lost their executive sponsor, and every signal after that points to a deal drifting from the inside. Next step: get a new sponsor mapped before you send anything else.
Same data. Same question. Completely different answer, because one system knows the sequence and the other one had to guess it.
Why Hockeystack
Other tools show you "related" activity. We show you what actually happened, in order, so revenue workflows can act on real sequence instead of inferring it.
- Built on a timeline model. Attribution and sequence analysis (first touch, last touch, "days since meeting," close plans) don't require additional engineering on top of the core data layer. First/last/sequence come from the same query. With Context Graphs, ordering is layered on top of a "related" model, so every feature and every agent step depends on that layer being correct and consistent.
- Pattern understanding. Because the data is natively ordered, we can answer questions like "deals where a meeting follows a content download within 7 days close at roughly 2x the rate", sequence-based insight that requires knowing when things happened relative to each other. That's the kind of pattern that's straightforward on an event stream and costly or brittle when you're re-sorting a set at every step.
- One data foundation for reporting and action. The same timeline powers dashboards, attribution, and agents (deal briefs, close plans, at-risk). No separate "related stuff" system that you turn into a story. So AI can assume "events for this deal, in order" and prescribe actions that match reality.
For revenue, the questions that matter are when and in what order. HockeyStack is built on an event-based timeline so those questions are native—and workflows don't have to guess the sequence.
Agents built for revenue teams need to understand what drives revenue. This comes from a timeline, not a graph.


Ready to see HockeyStack in action?
HockeyStack turns all of your online and offline GTM data into visual buyer journeys and dashboards, AI-powered recommendations, and the industry’s best-performing account and lead scoring.
Ready to See HockeyStack in Action?
HockeyStack turns all of your online and offline GTM data into visual buyer journeys and dashboards, AI-powered recommendations, and the industry’s best-performing account and lead scoring.